

AIDE
This project focused on developing and evaluating AI-based approaches to support the diagnosis and risk prediction of diseases, using publicly available clinical data. Several methods, including large language models and BERT-based classifiers, were explored and showed promising results, particularly in handling incomplete or sequential patient data. Building on these findings, a follow-up project is currently being planned to apply the developed methodologies to the KABEG Klinikum dataset. Discussions with partners are ongoing to define the next steps and ensure the successful transfer of the research into practice.
Goals
The goal of the project was to assist healthcare practitioners by enhancing the accuracy of endometriosis diagnosis and providing evidence-based treatment recommendations. The initial phase of the project involved a series of intensive workshops with leading professors and experts in endometriosis from Austria, Germany, and Switzerland. The primary aim was to gain a deep understanding of the current decision-making processes ("as-is") and to identify opportunities for improvement and optimization. These discussions informed the development of a clinically grounded AI approach focused on reducing diagnostic delay, minimizing reliance on invasive procedures, and integrating multimodal data, including imaging, symptom records, and clinical notes, into a unified analytical framework. In the long term, the project aims to support the development of a robust clinical decision support system (CDSS) that delivers interpretable, real-time recommendations to clinicians, streamlining diagnosis and improving patient outcomes across diverse healthcare settings.
Approach
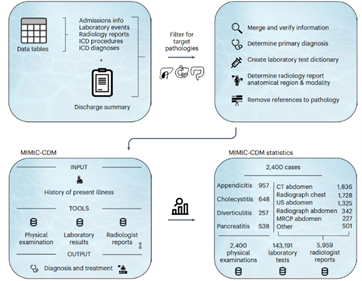
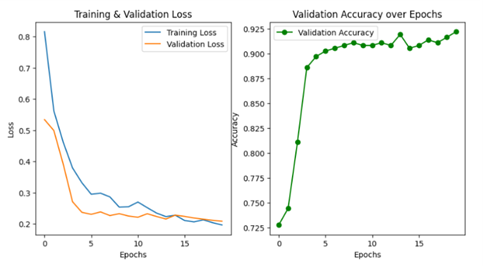
The initial phase of the project focused on replicating the diagnostic workflow as outlined by the MIMIC-CDM framework, adapted for the context of Endometriosis diagnosis. This framework utilizes large language models (LLMs) to simulate clinical reasoning from symptom onset through diagnosis and treatment planning. To supplement the generative LLM approach, a classification-based method was also developed. Following the AD-BERT methodology, a Bio_ClinicalBERT model was fine-tuned on structured clinical text from the MIMIC-CDM dataset. Only the final four hidden layers were updated during training to maintain generalizability while preventing overfitting. A lightweight classification head was trained using patient history and physical examination notes to predict disease presence.
Expected and Achieved Results
Ethics applications were submitted to and subsequently approved by both Johannes Kepler University (JKU) and the KABEG Klinikum, ensuring compliance with ethical standards and data governance regulations. Although preparations for the clinical data transfer, such as legal agreements, technical infrastructure, and data handling protocols, were initiated promptly after approval, the process encountered unforeseen administrative and logistical delays.
To maintain the project timeline and ensure continuous methodological development, the decision was made to use publicly available datasets as an interim solution while awaiting full access to the clinical data. The MIMIC-IV Extended dataset in Common Data Model (CDM) format, available via the PhysioNet platform, was selected for this purpose. This dataset includes de-identified health records of over 60,000 ICU patients and captures a wide range of clinical information such as diagnoses, procedures, medication prescriptions, lab measurements, radiology reports, and clinical outcomes. Its high-quality structure and compatibility with CDM standards made it particularly wellsuited for rapid prototyping, model training, and benchmark testing. Utilizing MIMIC-IV-CDM allowed the project team to replicate realistic diagnostic workflows and evaluate the performance of both generative and discriminative AI models under conditions similar to those expected with the KABEG dataset. The flexibility of the dataset also enabled simulation of incremental data availability, a key aspect of the planned decision support system.


