

KAL-GISS
To achieve technological advancements in production machines, gaining a comprehensive understanding of their inherent processes is crucial. Data analytics plays a pivotal role in attaining this understanding by processing data originating from these production machines. Specifically, for this project with ENGEL, the focus is on the plastic injection molding process. The data we analyze contains various signals generated by the production machines, encompassing parameters such as pressures, volumes, temperatures, specifics about the manufactured parts, and many more. At ENGEL, a diverse range of products is manufactured, ranging from small toy pieces to large plastic storage utensils, which presents unique challenges as this variety is reflected in the data.
In this project, our primary objective is to create models that can effectively classify and categorize specific features within these production processes. By harnessing the power of data analytics, we aim to gain insights that will enable us to derive insights that help improve the technological advancements in the injection molding process for ENGEL and its customers.
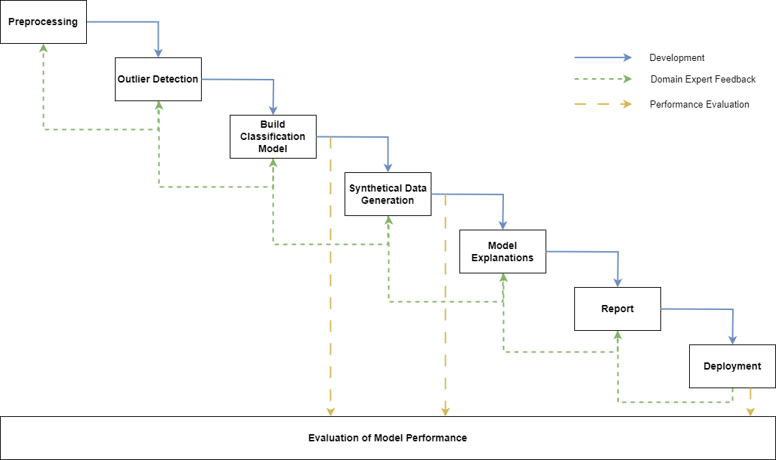
The data preparation process plays a vital role in this project, as it holds the key to discovering insights that hold value to the domain experts. We engage in close collaboration with those experts, working together to develop a robust strategy that takes into consideration all nuances and intricacies of the data. By understanding the challenges presented by the data originating from production machines, we define a set of features that will enable the model to generalize effectively to the underlying process. This important stage of preprocessing then empowers the model to discern patterns and relationships that contribute to improving the understanding of the plastic injection molding process from a data-driven point of view.
Goals
Prediction of injection molding machine specific parameters
The primary objectives of the KAL-GISS project revolve around establishing a robust data analytics pipeline capable of modeling the plastic injection molding process in a versatile manner. By crafting a well-defined set of features and employing customized state-of-the-art machine learning models, we aim to unlock a multitude of possibilities to create insights from historical data.
One example application is to infer the type of plastic material that was processed on a given machine for certain samples. This information is of interest to the partner company for various reasons. An example use case would be in service cases where decision support on the probability of certain parameters from the model leads to improvements in maintenance and repair processes that are done by service technicians.
Discovering causal structures in injection molding processes
To make informed decisions, a substantial amount of understanding of the relationships of the process-inherent variables is needed. Opposed to basic correlations, causal discovery can achieve insights that are closer to the true nature of the underlying process. Part of the project was to employ methods that uncover such causal relationships.
Approach
After analyzing the current state of the data, we dedicate a fair share of resources to improve a) the quality of the data and b) our understanding of the data by having the domain experts and their valuable knowledge in the loop. After the data is in a suitable state we start finding sets of features and models that fit this data. Again, this is an iterative process of presenting results and employing feedback from the plastic injection molding area of expertise. As a result, we obtain machine learning models that can predict certain parameters which can provide decision support for the aforementioned scenarios. For discovering causal structures, we intend to use the same, cleaned data that we obtained in the previous step. Different causal discovery algorithms are tested and the found structures are discussed and modified according to the domain knowledge.
Expected and Achieved Results
The expected results include a pipeline (see Figure 1) that takes as input the raw data that stems from the machines in production and outputs data that fits the needs for the downstream tasks such as classification, regression, and causal discovery. This takes care of missing or ill-defined data as well as the removal of samples that are considered anomalies in the given context. Selecting a feature set that is as little as possible but still contains the needed information is also part of this process.
The key contribution of our project lies in developing models that describe the manufacturing processes using preprocessed data. These models serve a dual purpose. Firstly, they have the capability to predict important parameters accurately, enabling stakeholders to make well-informed decisions with confidence. Secondly, these models offer valuable insights into the underlying cause-effect relationships present within the data, shedding light on the fundamental structures governing the manufacturing processes.
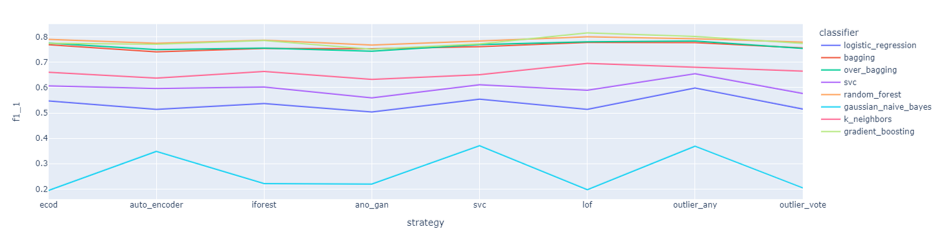
As of now, the data preprocessing is implemented, and a reduced feature set has been derived that is performing well on some benchmark prediction tasks. We are still in the process of designing causal discovery algorithms to extend the general understanding of the injection molding process.

