TrustInLLM
Modern Society increasingly relies on complex digital systems. It is crucial that such systems are trustworthy when Artificial Intelligence is involved, in particular Large Language Models (LLMs). The main motivation for this project is to increase the trustworthiness of these systems, especially focussing the topics: Transparency, Reliability and Safety.
Trust is a human concept, and trustworthiness implies the trait of deserving trust. This means, a trustworthy LLM system needs to be both, capable of generating reliable outputs (e.g., an answer), as well as, being perceived as trustworthy by users. In some cases of today’s LLM systems, exactly this trait is missing. With a tendency to return unreliable or spurious results (e.g., hallucinations) and a blackbox nature, which renders workflow transparency almost completely impossible, some language models solicit enormous scepsis in users. Thus, a human-centred approach is inevitable to design trustworthy AI-systems that involve LLM inference.
By using Transparency principles, obfuscated workflows can be designed clearer enabling users to better understand how answers were generated. Traceability can be used to emphasize the connection between (training) and the content of the provided response. These aspects can be achieved by e.g., designing a Retrieval-Augmented Generation (RAG) system, where users can ask questions to their own documents (self-provided data) obtaining answers that are easily verifiable through the linkage of parts of the source documents.
To provide reliable results the system needs to (i) inform the user of its limitations and provide confidence levels which helps users to judge the quality of answers, and (ii) provide transparent and traceable responses, that can be easily verified by users. In addition to that, topics like Safety (i.e., avoiding harmful, dangerous or biased responses), Privacy (i.e., taking the provenance of source data) and the safe handling of user data (system inference and provided documents) must be considered. Finally, particular emphasis is placed on the design of user interfaces (UI), with a strong focus on human-centred design principles.
Goals
The overall goal of this project is to achieve a foundational approach towards ensuring trustworthiness of LLM-assisted systems. New methods and trust-related ontologies will be devised for elicitation, specification and the design of trust-related mechanisms which innovatively consider both system and data qualities.
Initially the legal aspects of trustworthiness as required in the EU AI Act are investigated, also leading to research on relating trustworthiness with quality attributes of systems and data. Another goal is a partial requirements ontology for conceptually linking these quality attributes. Additionally, a preexisting Retrieval-Augmented Generation (RAG) framework will be continuously updated and enhanced throughout the project, acting as the main demonstrator for trustworthiness improvements. The evaluation of scientific approaches is based on a realworld use case of the Industrial Partner Bosch in the domain of Hardware Software Interfaces (HSI) that is a complex topic in automotive development. In this context the automation of complex and tedious manual labor with an LLM-assisted system is targeted.
Ultimately, to create a trustworthy LLM-assisted approach, the established system needs to be at least reliable, transparent and the (generated) data correct.
Approach
To build a trustworthy LLM-based AI system, a comprehensive literature review has been conducted, alongside a thorough investigation of relevant system and data requirements. Legal considerations are addressed in alignment with the EU AI Act. Requirements engineering is carried out both for trust-related aspects and for the existing documents and datasets used within the project. In parallel, the project’s Retrieval-Augmented Generation (RAG) framework is continuously refined and evaluated throughout the development process. Humancentered UI design is pursued through iterative user interviews and user studies. Finally, the RAG system is evaluated and validated using domain-specific documents from the Hardware-Software Interfaces (HSI) field, provided by the project partner Bosch.
Expected and Achieved Results
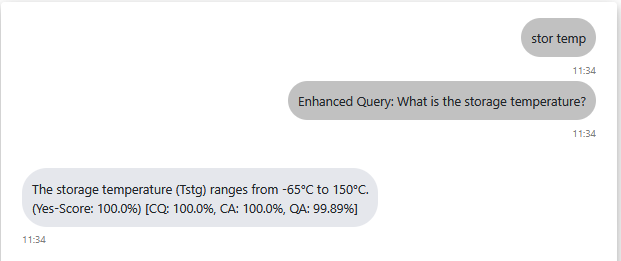
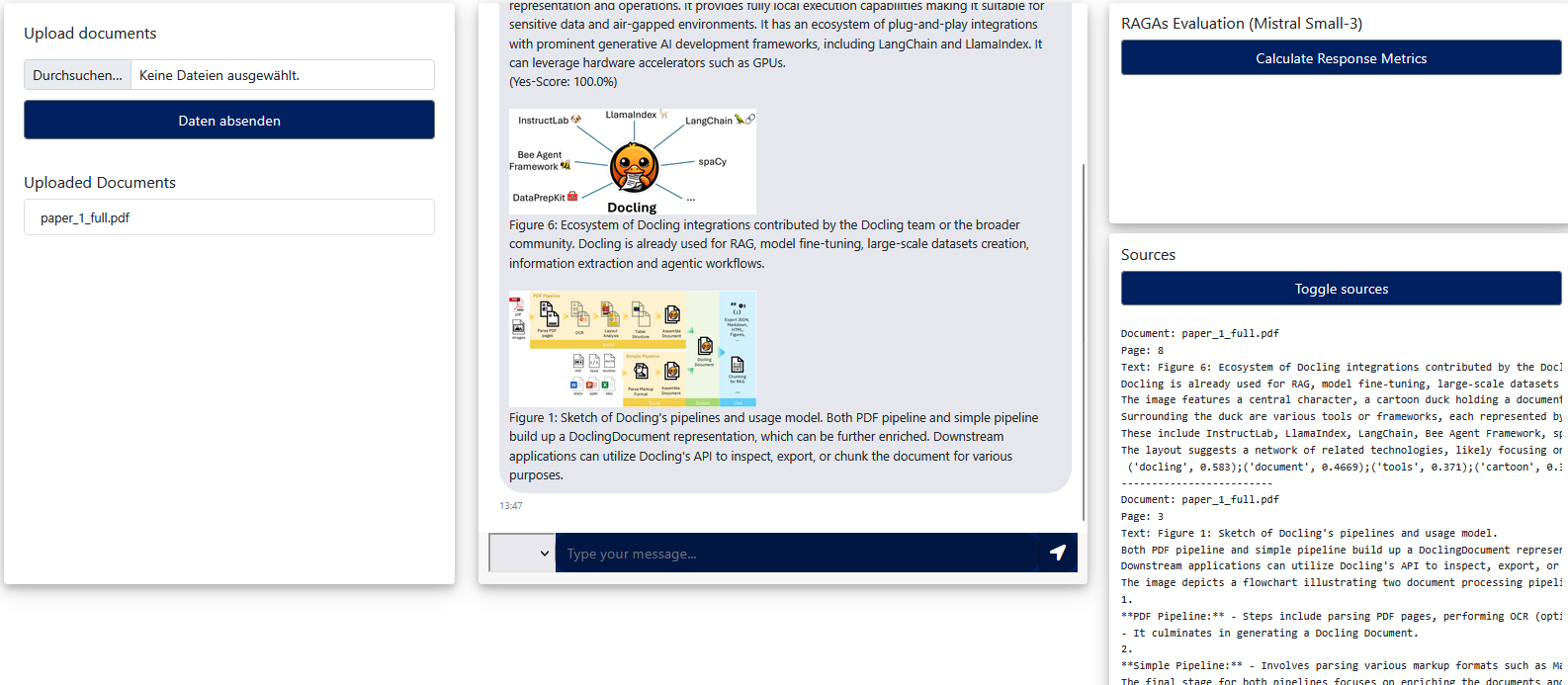
During the initial phase of the project, P2F’s pre-existing RAG system (AERIALL) was reactivated and adapted for the project’s specific objectives. This included a series of updates aimed at enhancing the system’s structure, overall performance, and responsiveness. The RAG system’s foundation was upgraded by replacing the previously used Mistral-7B with more capable open-source models, now supporting Mistral-Small-3, Mistral-Nemo, and DeepSeek-R1. Additionally, evaluation capabilities were integrated into the system, including RAGAs metrics and the Yes-Score, both implemented using a self-hosted LLM. Selecting an open-source and locally hostable LLM was inevitable to create a trustworthy AI system. One the one hand, open-weight models enable the creation of transparent workflows by allowing access to their parameters. On the other hand, a locally hosted model provides the highest level of data security when working with LLMs, as all documents and data remain securely within the local network.
To further mitigate known inference challenges of LLM, such as hallucinations, additional re-retrieval mechanisms were incorporated into the RAG system. These mechanisms significantly improved the system’s accuracy by optimizing the retrieval of the most relevant source chunks. Query Rewriting, refines user inputs to make them more precise, thereby reducing the likelihood of hallucinations caused by vague or ambiguous questions. Another method, Hypothetical Document Embeddings (HyDE), simulates an ideal target document to provide richer context during the retrieval phase. This reduces the risk of retrieving irrelevant or incorrect chunks that could lead to false answers from the LLM.
Additional efforts were made to incorporate multimodal elements embedded in document, such as images and tables, into the LLM-generated responses. To achieve this, a dedicated preprocessing pipeline was developed, allowing for the creation of specialized chunks tailored for effective retrieval. Furthermore, a visual model (YOLOv9) was trained to detect and extract pin diagrams from documents, enabling subsequent processing and integration of these diagrams into the system’s outputs.