

E-Minds-1
The objective of this project is to provide techniques and toolchains that make it possible to train and deploy AI/ML models for embedded systems with little resources. This should allow the use of trustworthy embedded intelligence in the future in cognitive products and production systems. The project will showcase the created methodologies and toolchains by applying them to industrial case-studies.
Goals
In today's swiftly changing tech landscape, two vital domains emerge: creating AI/MI models for resource-constrained embedded systems and integrating Cognitive Wireless Sensing into evolving wireless communication, especially in the context of 6G research priorities. Our exploration delves into these contexts, examining efficient AI/MI model creation and seamless Cognitive Wireless Sensing integration.
We're crafting a comprehensive training framework. This encompasses data collection, evaluation, training technique selection, and model provisioning. To achieve optimal results, we aim to:
- Integrate varied training frameworks and concepts from different MFPs and literature.
- Investigate compression principles for simplifying models for embedded device use.
Efficient model deployment onto designated devices is central to our project. We're actively developing semi-automated toolchains for streamlined implementation. The designed toolchain's demonstration aligns with the specifications from the "Enhancing UWB with Embedded Intelligence" case study. We're meticulous in selecting and developing the case study to ensure accessible training data, methodologies, and efficient measurement models for embedded ML models.
Approach
Firstly, to ensure the successful outcome of our work, our approach begins with an in-depth exploration of existing training frameworks, concepts, and methodologies in the literature about embedded intelligence .
Moving forward, our trajectory involves the selection of diverse models and techniques that align seamlessly with the ground truth of our task. These chosen models must inherently adhere to the constraints imposed by our task's model, including factors like timing considerations.
With our chosen models in hand, our next step entails deployment through a meticulous process involving compression and pruning techniques drawn from existing literature. This strategic approach aims to optimize the models while maintaining their integrity and performance.
Subsequently, the culmination of our efforts leads to the presentation of our meticulously developed toolchain in the form of a demonstrative showcase, prominently featuring the advancements made in the realm of "Enhanced UWB." This showcase serves as a testament to the effectiveness and practicality of our approach.
Basing our insights on thorough scientific research, we have identified a set of foundational points that can serve as a starting base for addressing and aligning with the previously mentioned key approaches:
- To achieve the compression and portability of various types of models, it is essential to consider multiple frameworks. For instance, the MicroML Library demonstrates the capability to port several types of models, such as Decision Trees (DT) and Support Vector Machine (SVM) models, while not accommodating Perceptron’s. On the other hand, the Micro Learn Library specializes in porting Perceptron’s and for DTs.
- Conducting an evaluation of these frameworks becomes imperative to showcase their respective strengths and compatibility with different models. This assessment will show which framework is most suitable for specific types of models, optimizing their performance .
- The process of generating versatile files from the porting frameworks extends beyond the typical showcasing solely on platforms like Arduino. To ensure broader usability across various MCU implementations, two critical points must be addressed: (i) Framework Adaptation and Tailoring: The first imperative involves adapting and tailoring the framework outputs to harmonize seamlessly with diverse MCU environments; and (ii) C-Library Generation for Runtime Adaptability: The second focal point centers around the generation of libraries featuring specific models. These libraries should possess the capability to adapt dynamically during runtime on the MCU by remote commands. This approach can facilitate a broader and more adaptable implementation, allowing for increased flexibility and versatility.
Hardware requirements: To obtain an accurate performance estimation for various applications under different constraints, it is imperative to apply the techniques across distinct categories of hardware. This entails evaluating the techniques on the following HW-categories:
- Slower Hardware without FPU and DSP Instructions: This category involves hardware configurations that lack Floating-Point Unit (FPU) and Digital Signal Processor (DSP) instructions, which often pose limitations on computational capabilities (e.g., ESP8266).
- Hardware with FPU and DSP Instructions: The second category encompasses hardware equipped with FPU and DSP instructions, allowing for enhanced computational capabilities (e.g., ESP32).
- For a thorough evaluation, it's crucial to include hardware customized for the intended purpose. This specialized hardware should closely match the applications, shedding light on techniques' real-world performance and suitability. A prime example of this is the nRF52833, coupled with the DW1001, which aptly suits Ultra-Wideband (UWB) applications and is prominently featured in the literature.
- A larger memory space provides testing advantages. Despite optimizing models for constrained memory, having more memory allows realistic testing of significantly reduced models. Larger memory accommodates larger ML models, facilitating accurate reduction estimation without immediate implementation constraints. This comprehensive approach enhances reduction potential assessment.
- Communication capability: For smooth and flexible communication while in motion, it's crucial to support device interaction during operation. This means being able to adaptively transfer data and model parameters on the fly, especially for live demos. To achieve this, equipping the hardware with an additional wireless communication port becomes important, enhancing its versatility and practicality.
Expected and Achieved Results
Our project encompasses several key objectives. Firstly, we aim to develop efficient techniques for model selection and training within the domain of embedded intelligence. Furthermore, we are confident in our ability to devise methods that assess and validate the correctness and behavioral aspects of models, including their timing characteristics. Additionally, we are dedicated to refining methods to optimize model sizes for deployment on embedded platforms. Our focus also involves creating seamless and automated deployment processes for specific embedded devices, seamlessly integrated into our training platform. Moreover, we are enthusiastic about data collection and plan to implement machine learning-based approaches to enhance applications of Ultra-Wideband (UWB) technology. These combined efforts will culminate in a demonstrator that effectively showcases our accomplishments. Guiding our endeavors is a structured framework that serves as a roadmap to attain these objectives.
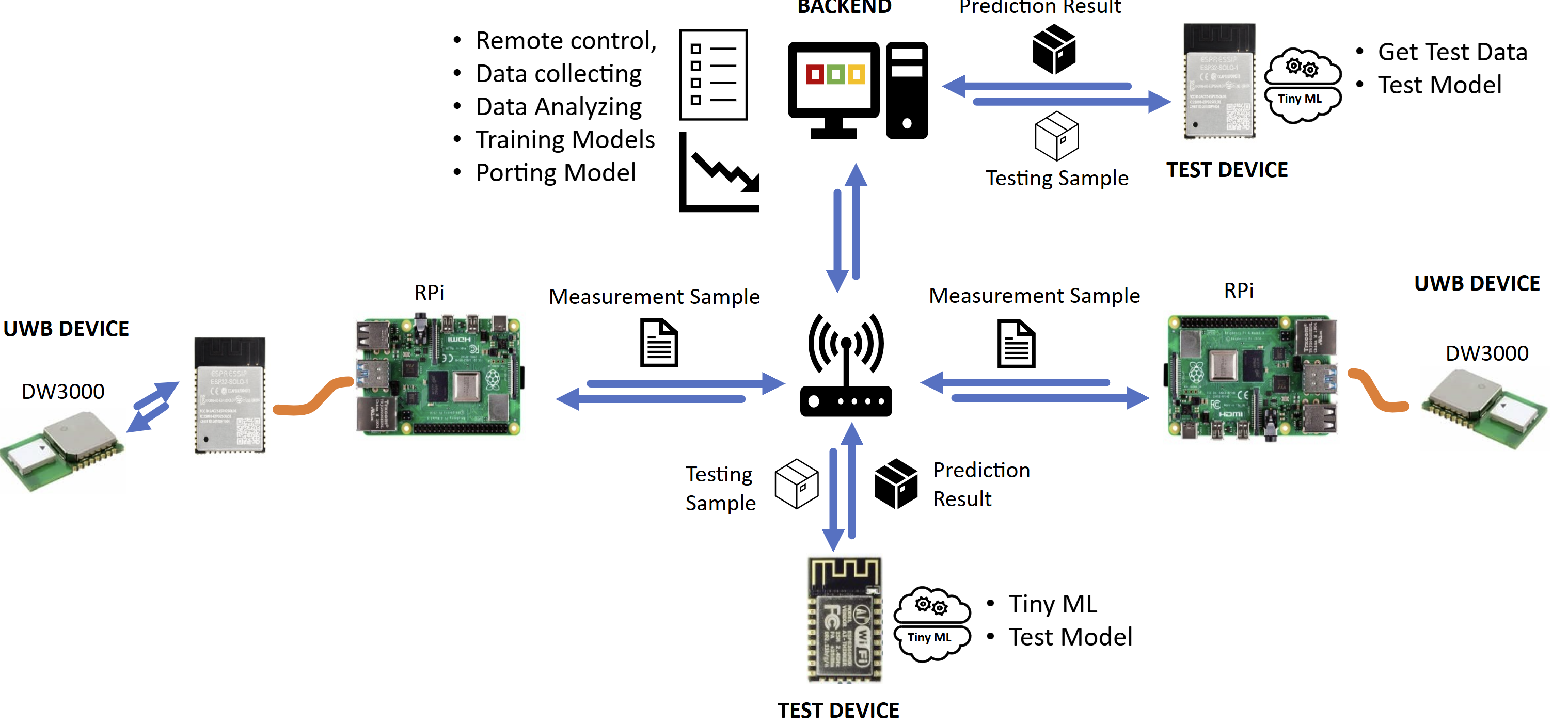
Example: Toolchain/Demonstration Framework Architecture
Figure 1: Demonstrates a key research outcome - the creation of a measurement and testing framework. The UWB devices are connected to a Raspberry Pi, which acts as a forwarding and flash device, channeling data to our Backend for collection. The measurements collected can be sent to an MCU without an existing UWB driver. The MCU receives continuous test data for model evaluation. During testing, performance metrics such as prediction duration, outcome, and memory usage are sent back to the backend for further analysis. This structure results the advantage to offer dual capabilities: real-time data execution and testing using stored test data. This allows for comparing the original model to its scaled-down version. Furthermore, verification primarily focuses on the MCU, negating the need for extensive implementation with other hardware.
The approach facilitates testing the same model across diverse hardware setups, enabling the creation of a hardware/model benchmark.
