

3D-RECON I
The aim of 3D-Recon is the research and development of methods for high quality 3D reconstruction from images in two dimensions: (i) making use of deep neural networks for higher precision and accuracy on camera positioning and (ii) making use of deep learning and computer vision in 3D reconstruction. In a first step the project will focus only on reconstruction of static scenes, i.e. rooms and not on dynamic scenes which e.g. include moving humans. The fundamental goal of the project is to provide improvement on existing benchmarking data from the scientific community as well as company partner Sony.
The project team believes that Deep Neural Networks (DNNs) have the potential to improve the quality of image-based 3D reconstructions, which could be at a very later stage be used by millions of users equipped with cameras in there smartphones, while e.g. laser based solutions will never be a commodity good.
In order to leverage this benefit, in a first step the project team aims to improve 3D reconstructions, using neural networks on high-resolution image datasets as available by the ETH3D benchmark and using them for geometric image-based 3D reconstruction. With this approach, we foresee that especially in areas where traditional methods fall short, e.g. surfaces like large walls, ceilings or floors a substantial improvement beyond the state of the art can be made.
The improvement will be made in two areas of multi-view stereo (MVS) pipelines, which are like classical two-view stereo methods, which build up a cost volume by matching image patches along the epipolar line. MVS however construct a cost volume by computing costs for a set of given plane hypothesis. The first area of improvement will be confidence prediction which is an inherent part of MVS methods. It calculates costs by local patch comparison based on metrics like e.g. Normalized Cross Correlation. The second area of improvement will be depth refinement, since there MVS methods tends to fall short in untextured areas, e.g. walls, where the matching becomes ambiguous. Here most 3D reconstruction pipelines include a refinement step meant to remove depth outliers or even estimate missing depth areas. Often these methods rely on a confidence map, as it is critical to understand which depth map areas are reliable and which need to be extended.
Overall, we aim to compare our improvements on the multi-view stereo reconstruction methods with existing approaches on scientific benchmarking sets like COLMAP or ACMM.
Goals
3D-Recon has the goal to advance 3D Reconstruction in two dimensions (i) making use of deep neural networks for higher precision and accuracy on camera positioning and (ii) making use of deep learning and computer vision in 3D reconstruction. In a first step the project team aims to improve in these areas, using high-resolution image datasets as available by the ETH3D benchmark and using them for geometric image-based 3D reconstruction. With this approach, we foresee that especially in areas where traditional methods fall short, e.g. surfaces like large walls, ceilings or floors a substantial improvement beyond the state of the art can be made. The project will focus at this stage solely on static scenes where there are no dynamic objects moving in front of the camera. Advancing image-based 3D reconstructions, has the benefit, in comparison to laser-based solutions, that they could be used at a very later stage by millions of users equipped with cameras in their smartphones.
Approach
3D-Recon will build on- and advance over state-of-the-art methods for multi-view stereo pipelines.
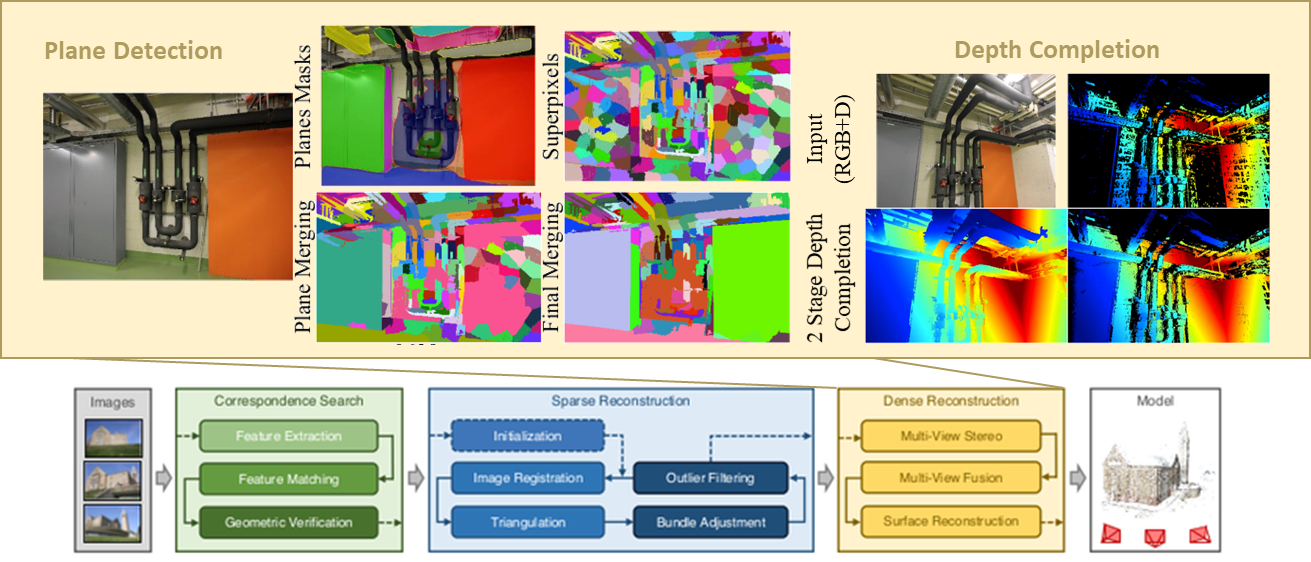
The first area of improvement will be confidence prediction which is an inherent part of these pipelines. It calculates costs by local patch comparison based on metrics like e.g. Normalized Cross Correlation. Here we use pixel-wise estimation of the expected noise in the 3D space based on trained data from a neural network. The second area of improvement will be depth Refinement, since there MVS methods tend to fall short in untextured areas, e.g. walls, where the matching becomes ambiguous. Like most 3D reconstruction pipelines we include a refinement step meant to remove depth outliers or even estimate missing depth areas. Here build upon a pretrained plane detection neural network and super pixels to estimate the true planes in a 3D space.
Expected and Achieved Results
We aimed to establish a large improvement on accuracy and precision by estimation the camera position in a structure from motion system, with the ultimate goal to enable improved and comprehensive reconstruction of indoor rooms, with large quantities of low textured planes like walls, ceilings, or floors in contrast to existing state of the art solutions.
This new approach was developed in a software pipeline and applied to various kind of benchmarking datasets of the scientific community and demonstrate the feasibility of image based 3d Reconstruction. The areas of improvement in our multi-view stereo approach are in confidence prediction and depth refinement, two steps which are crucial to 3D reconstruction from images. In both areas we made use of deep neural network to advance our overall method.
This was achieved by confidence prediction networks which have been adapted to the Multi-View Stereo (MVS) case and are trained on automatically generated ground truth established by geometric error propagation. We demonstrated the utility of the confidence predictions for the two above mentioned steps in outlier clustering and filtering and additionally in the depth refinement step, shown in the Figure.

